Interprétation et diagnostic d'un incident en production.
Interprétation pas à pas d'un incident sur infrastructures applicatives, cas pratique d'un incident vécu.

Préambule
Premier article concernant la résolution d'incidents, toujours à but de formation. N'ayant jamais vu beaucoup d'articles traitant du sujet il nous parait intéressant d'expliquer et commenter les post-mortems qu'il nous arrive d'envoyer à nos clients. C'est aussi, à notre avis, une bonne façon (si ce n'est la meilleure) d'expliquer pourquoi le DevOps est important dans les métiers SRE, à quoi il sert et comment nous utilisons les outils que l'on met en place.
Gardez à l'esprit que chaque applicatif est unique (même si l'on retrouve des comportements type) et que l'un des meilleurs indices d'anomalie et « l'écart par rapport à la moyenne normale », autrement dit un comportement qui diffère fortement de ce que vous avez l'habitude de voir.
Pour finir, c'est l'exercice le moins « confortable » du métier. En fonction de sa gravité, l'incident infra peut passer inaperçu comme impacter de manière significative l'activité d'un client, l'expérience des équipes dans ce cas de figure est souvent un facteur clé pour la rapidité de la résolution.
Contexte
Le contexte est assez classique pour de l'application web.
- Un applicatif métier « relativement » pas mal utilisé en journée recevant environ 240 requêtes/s (Réparties à 80% sur l'API, les 20% restant étant dédié à du back-office);
- 6 frontaux web (Nginx / PHP-FPM);
- 1 répartiteur de charge managé;
- 1 répartiteur de charge SQL MaxScale;
- 2 instances MariaDB en configuration « Primary / Replica ».
En complément:
- L'API répond principalement à une application mobile;
- Le back-office déclenche l'envoi de notifications (~ 800 000/jour) vers ces mêmes applications.
Déroulé de l'incident
- Durée totale de l'incident: 1h20
- Impact: Significatif
- Type: Indisponibilité complète
Comme tous les incidents, nous sommes alertés par nos sondes infra:
Il n'est pas rare d'avoir des alertes isolées dues à une défaillance d'un hyperviseur ou à une panne réseau, dans notre cas de figure l'effondrement de l'infrastructure est très rapide (inférieure à 3 minutes), aucun doute donc sur « un gros pépin ».
Les alertes infras se terminent par une alerte StatusCake sur le « endpoint » applicatif HTTP configuré.
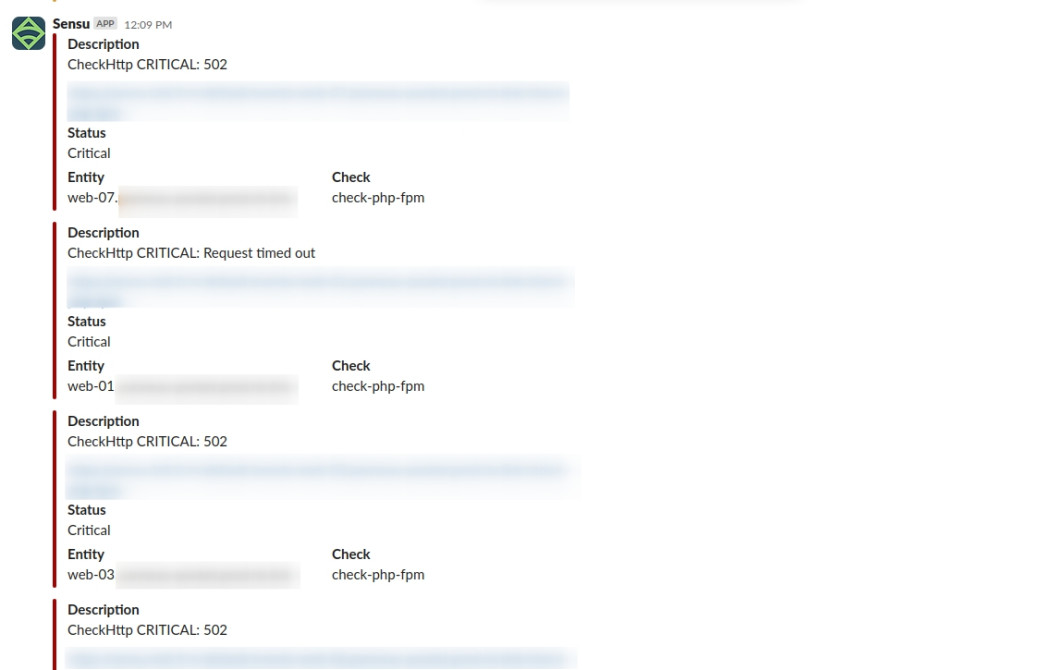
Nous notifions à notre client le début de l'incident et le début d'analyse pour remédiation.
Diagnostic infra
Elles sont systématiques en cas d'incident et consistent en une checklist assez simple:
- Vérification de l'état des instances;
- Vérification d'un incident déclaré chez le fournisseur de cloud (ici OVHCloud);
- Vérification de la connectivité des réseaux privés.
En seconde étape nous procédons à une première analyse des « graphs » sur quelques unes des instances applicatives:
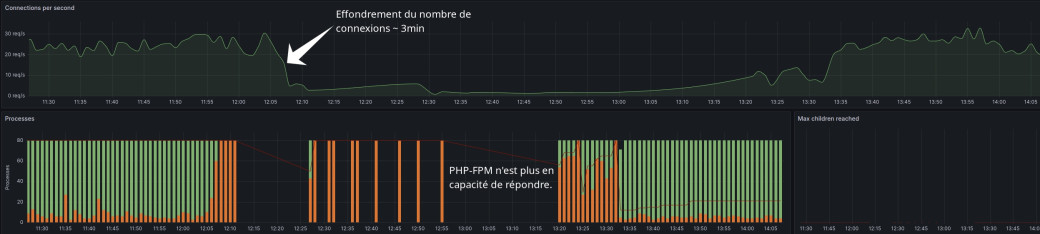
Pour autant les instances n'apparaissent pas « chargées » outre mesure.
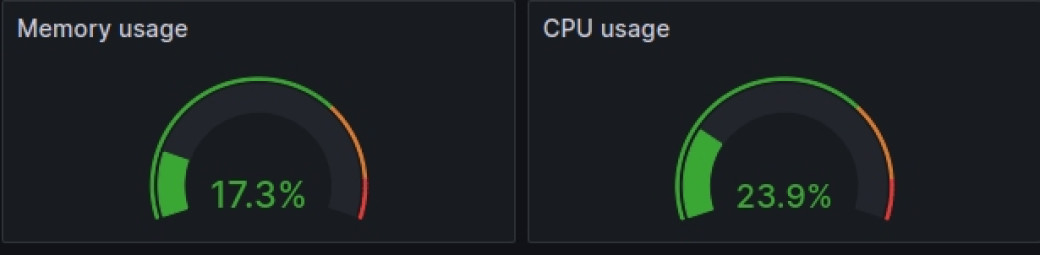
Sur l'ensemble des instances nous ne constatons pas d'augmentation de la consommation des ressources, de même le traffic n'explose pas, nous ne sommes donc pas dans le cas d'un afflux massif de connexions (légitimes ou non d'ailleurs), ni d'une charge anormale du à un script mal conçu.
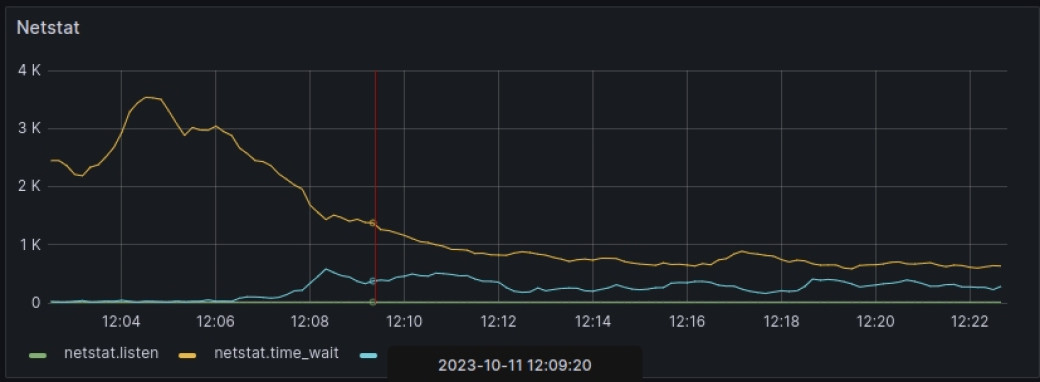
Nous disposons toutefois d'un premier indice au niveau réseau, puisque nous constatons une augmentation des connexions « ouvertes » et une chute flagrante des connexions en attente de fermeture.
Nous avons également constaté que les médias applicatifs sont bien disponibles et que nous n'avons pas de coupure vers les espaces de stockage distants.
À ce stade nous avons donc une infra fonctionnelle mais une application « dans les choux ». Nous tentons une première approche en redémarrant les services PHP-FPM sur l'ensemble des instances, ceux-ci se retrouvent rapidement à nouveau saturés et hors service, comportement qui semble confirmer un souci d'ordre applicatif.
Diagnostic applicatif
Il est temps d'aller jeter un oeil aux logs applicatifs qui donnent rapidement un résultat puisque nous avons l'erreur suivante:
SQLSTATE[HY000]: General error: 2006 MySQL server has gone away at XXXXXXXNous avons donc bien une perturbation au niveau de la connectivité entre les instances applicatives et les instances de base de données, reste à déterminer la raison !
À ce stade nous prenons contact avec l'équipe de développement applicatif afin de disposer de sa connaissance métier et fonctionnelle.
Analyse des métriques
Nous poursuivons nos investigations à l'aide de nos métriques infra / applicatif plus spécifiquement sur le réseau privé, zone d'échange entre les instances applives et données pour y trouver ceci:
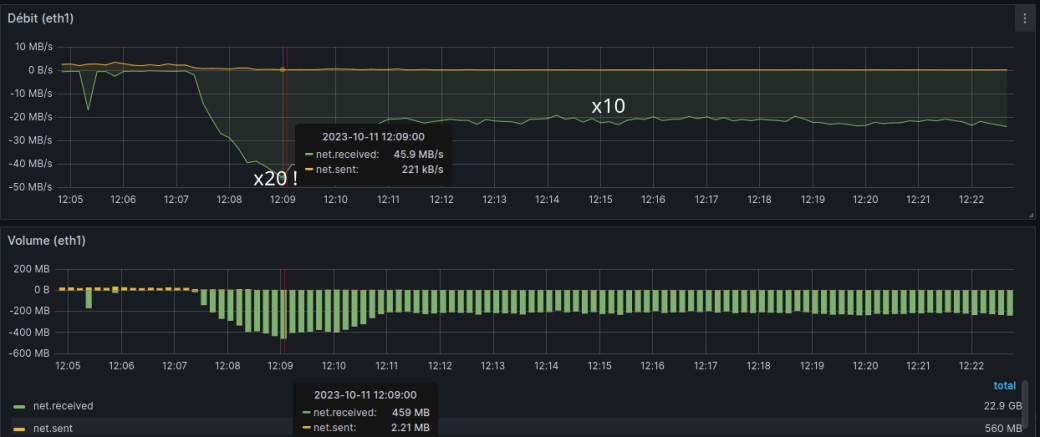
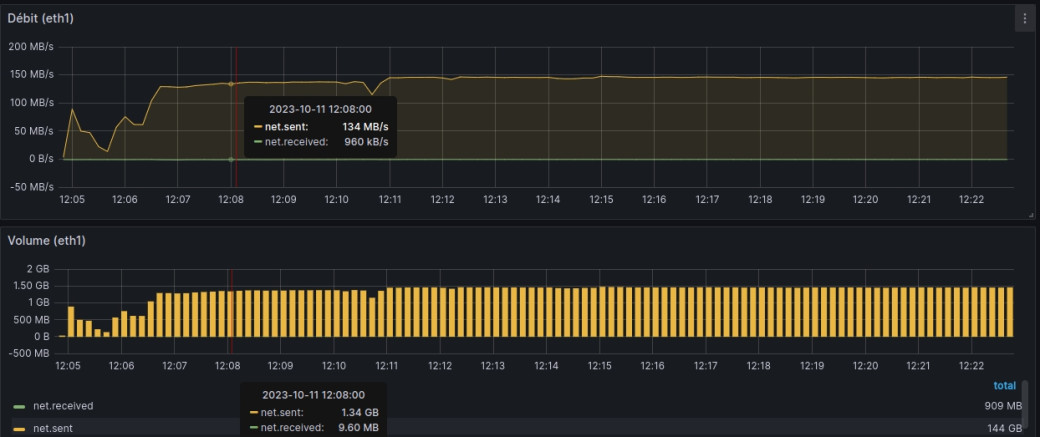
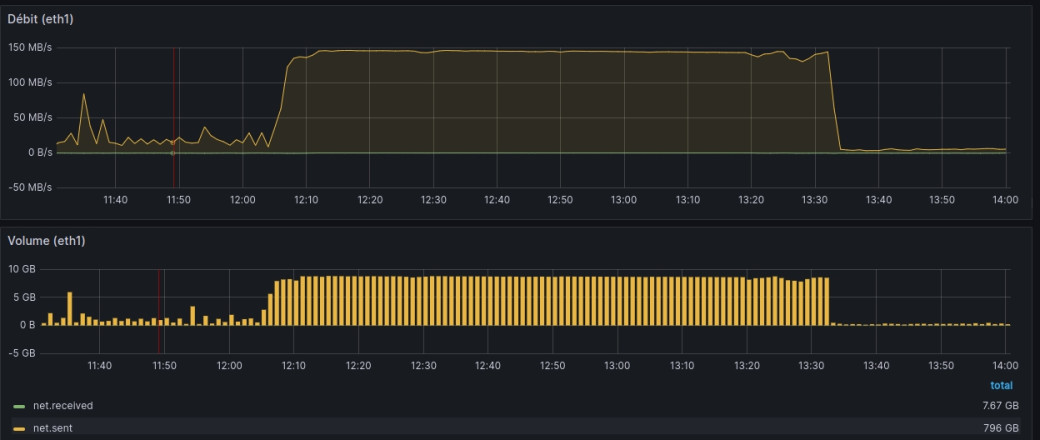
Enfin du concret ! On constate à l'aide de ces deux graphs une volumétrie de données d'échange anormalement élevée entre les instances applicatives et les instances de base de données.
Constat:
- En entrée des instances applicatives (1) nous avons un débit x20 qui passe de 2~2,5MB/s en moyenne à 45MB/s pour ensuite se stabiliser à hauteur de 20~25MB/s;
- En sortie des instances de base de données (2) un débit moyen qui explose (x7) pour s'installer à hauteur de 150 MB/s.
On constate surtout que cette volumétrie vient saturer la bande passante avec un bel « effet plafond » du graph concerné (3).
Nous avons donc la cause de l'incident à savoir, la saturation de la bande passante entre les instances applicatives et les instances de base de données, ce qui conduit à une grosse attente au niveau PHP-FPM qui se retrouve dans l'incapacité de prendre de nouvelles connexions entrantes.
Au passage, on voit ici l'importance de « caper » le nombre de connexions maximum que l'on autorise à PHP-FPM, dans le cas ou ce travail n'est pas et/ou mal fait ou si aucun seuil n'est fixé, nous pouvons avoir potentiellement une perte complète de la connectivité à l'instance applicative qui peut impacter de manière significative le temps de rétablissement.
Nous avons l'origine du blocage, il nous faut à présent comprendre d'où cela vient, nous passons donc du côté serveur de base de données.
Analyse des requêtes SQL
Afin d'identifier d'éventuelles requêtes problématiques nous jouons un SHOW PROCESSLIST sur notre serveur de base de données et isolons les requêtes en cours d'exécution depuis plusieurs secondes.
En rejouant l'une de ces requêtes nous constatons qu'elle est anormalement volumineuse (taille supérieure à 5Mo).
Plus spécifiquement elle « ramène » un champ d'une table bien précise et après échange avec les équipes applicatives il correspond à l'ajout d'un « relativement nouveau » fonctionnel, relativement parce qu'il a tout de même quelques semaines mais n'a, à priori pas été utilisé tout de suite par les utilisateurs finaux.
Le champ en question permet de stocker du contenu libre saisi par l'utilisateur à l'aide d'un éditeur de contenu (À ce moment là, certain(e)s d'entre vous doivent avoir une idée de ce qu'il se passe ;)).
Nous décidons de passer la publication concernée en « draft »... ce qui est sans influence directe sur la saturation de la bande passante.
Nous élargissons notre champ de recherche, cette fois-ci en recherchant les lignes disposant d'un champ de contenu dont la taille est supérieure au Mo (SELECT id ... WHERE CHAR_LENGTH(content) > 10000), pour finalement identifier une centaine de lignes présentant la même problématique.
Vu la gravité de la situation (indisponibilité complète de l'application) et en concertation avec les équipes applicatives nous « dépublions » l'ensemble des contenus problématiques ce qui a pour effet de faire revenir les échanges de données à un seuil normal et de facto rendre à nouveau disponible l'applicatif.
Dans le même temps les équipes applicatives auront préparé un « quick fix » désactivant la fonctionnalité, le temps de la retravailler.
Le fin mot de l'histoire
Il s'avère que l'application proposait un module de publication à ses utilisateurs embarquant un éditeur de contenus riches qui autorisait l'insertion d'images directement dans les contenus HTML (sans passer par un stockage sur le système de fichiers et donc directement en base de données). Cerise sur le gateau, nous sommes en 2023 et les images « brutes » pèsent souvent plusieurs Mo.
Conclusion
Ce cas est une parfaite illustration de ce que l'on peut avoir comme incident avec une application web, bien que l'origine soit assez sournoise, en effet il n'est pas déclenché par une mise à jour récente mais par un fonctionnel développé il y a plusieurs semaines, mais mis en avant que récemment. De plus, en première lecture, il n'y a pas d'incident apparent, ni charge anormale des instances, ni pépin réseau.
Les logs applicatifs permettent de s'orienter vers une cause probable de l'indisponibilité mais ne sont pas suffisants pour identifier de manière précise son origine, c'est leur corrélation avec la lecture des métriques qui permet de gagner énormément de temps sur le diagnostic et ainsi cerner le problème.
Les équipes applicatives sont un renfort précieux, pour dans un premier temps, fournir les informations de dernières mises à jour ou d'arrivée de nouveau fonctionnel (et surtout de mettre en relation un fonctionnel et un schéma de données) et dans un second temps pour corriger (même temporairement) le code, afin d'éviter une rechute inévitable.
Ce qu'il faut en retenir
- Éviter de stocker des médias en base de données qui plus est dans un champ « texte »
- Méfiez-vous des éditeurs de contenus riches et prenez le temps de bien les intégrer / configurer. Entre les potentiels dépôts de fichiers sauvages qui peuvent mettre en cause la sécurité applicative, l'injection de scripts et l'ajout de médias non optimisés c'est une source d'ennuis sans fin
- Monitorez vos infras !
- Intégrer les équipes applicatives au diagnostic
- Si vous en avez la possibilité, faites des tirs de charge !
- « Profile ! Don't assume.»